Planar Reconstruction - 深度学习之平面重建
 |
 |
 |
 |
|---|---|---|---|
| input image | piece-wise planar segmentation | reconstructed depthmap | texture-mapped 3D model |
0x00 Datasets
- ScanNet [1,3,4]
- SYNTHIA [2,3]
- Cityscapes [2]
- NYU Depth Dataset [1,3,4]
- Labeling method
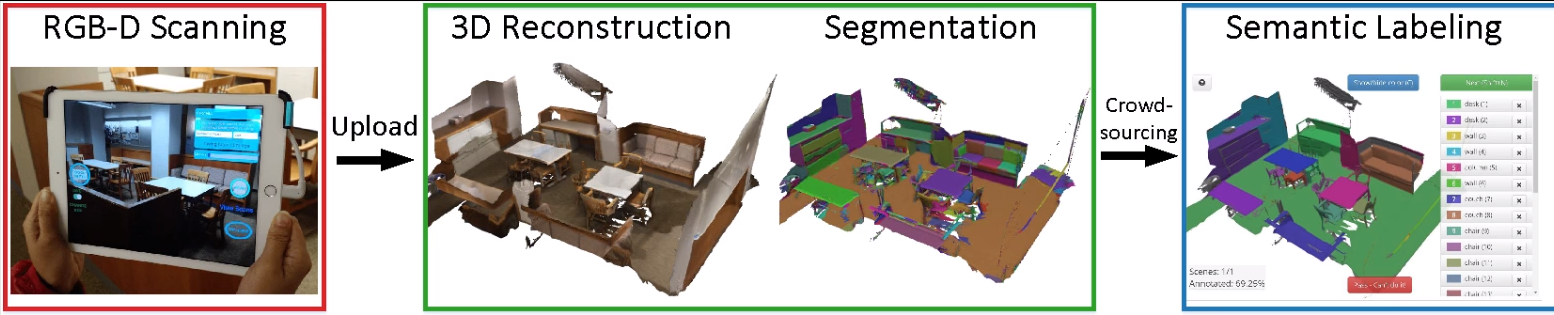
ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes. annotated with 3D camera poses, surface reconstructions, and instance-level semantic segmentations.
SYNTHIA: The SYNTHetic collection of Imagery and Annotations. 8 RGB cameras forming a binocular 360º camera, 8 depth sensors
Cityscapes: Benchmark suite and evaluation server for pixel-level and instance-level semantic labeling.
video frames / stereo / GPS / vehicle odometry

NYU Depth Dataset: is recorded by both the RGB and Depth cameras from the Microsoft Kinect.
- Dense multi-class labels with instance number (cup1, cup2, cup3, etc).
- Raw: The raw rgb, depth and accelerometer data as provided by the Kinect.
- Toolbox: Useful functions for manipulating the data and labels.

Obtaining ground truth plane annotations :
Difficulty in detect planes from the 3D point cloud by using J-Linkage method.
 |
|---|
| (c-d): Plane fitting results generated by J-Linkage with δ = 0.5 and δ = 2, respectively. |
Labeling method:
| ScanNet: |
|---|
| 1. Fit plans to a consolidated mesh (merge planes if (normal diff < 20° && distance < 5cm) |
| 2. Project plans back to individual frames |
| SYNTHIA: |
|---|
| 1. Manually draw a quadrilateral region |
| 2. Obtain the plane parameters and variance of the distance distribution |
| 3. Find all pixels that belong to the plane by using the plane parameters and the variance estimate |
| Cityscapes: |
|---|
| 1. “planar” = {ground, road, sidewalk,parking, rail track, building, wall, fence, guard rail, bridge, and terrain} |
| 2. Manually label the boundary of each plane using polygons |
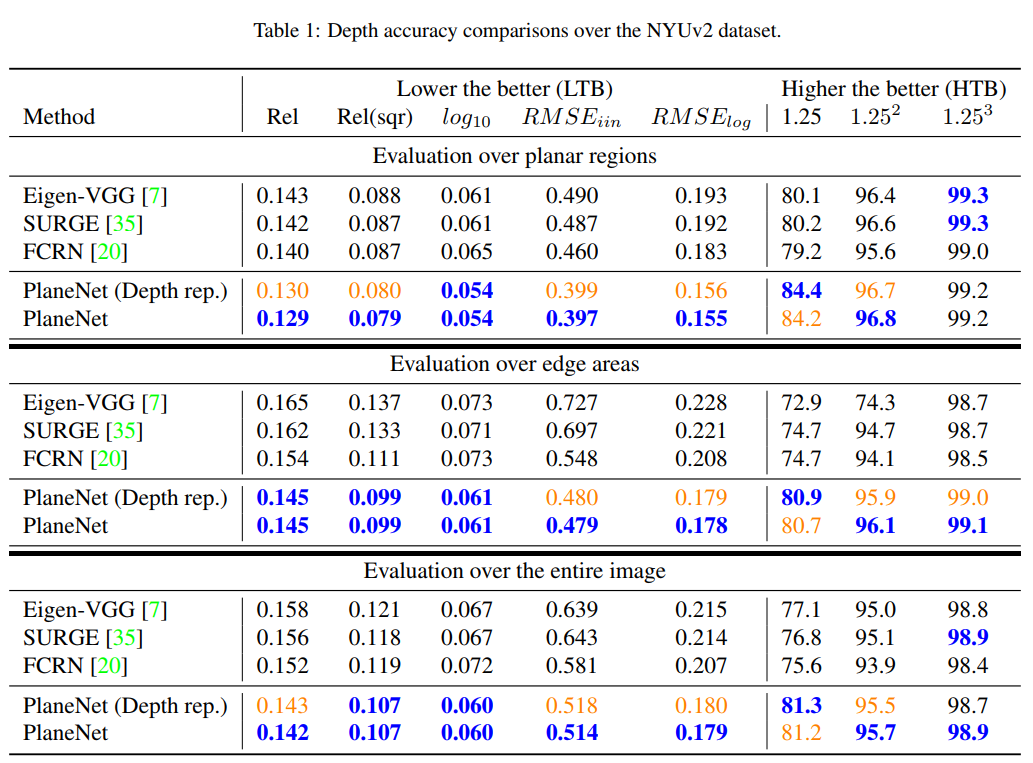
0x01 PlaneNet
[CVPR 2018] Liu, Chen, et al. Washington University in St. Louis, Adobe.
The first deep neural architecture for piece-wise planar depthmap reconstruction from a RGB image.
Pipeline
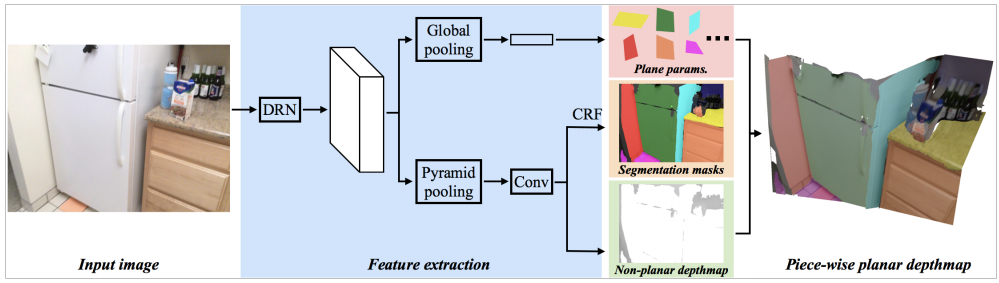
DRN: Dilated Residual Networks (2096 channels)
CRF: Conditional Random Field Algorithm
| Step | Loss |
|---|---|
| Plane parameter: | |
| Plane segmentation: softmax cross entropy | |
| Non-planar depth: ground-truth <==> predicted depthmap | |
| - |
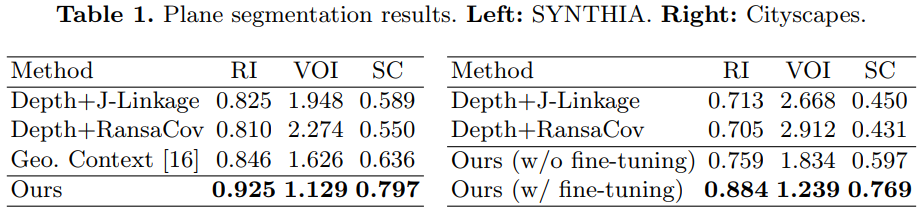
0x02 Plane Recover
[ECCV 18] Fengting Yang and Zihan Zhou Pennsylvania State University.
Recovering 3D Planes from a Single Image. Propose a novel plane structure-induced loss
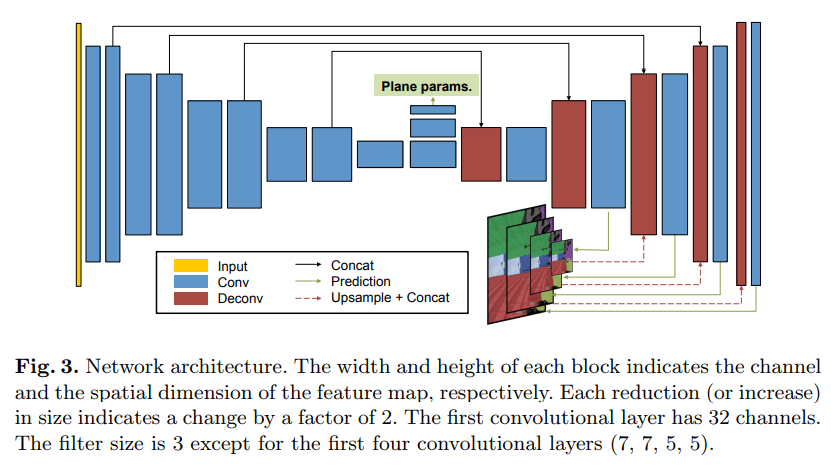
| Step | Loss |
|---|---|
| Plane loss | |
| Loss |
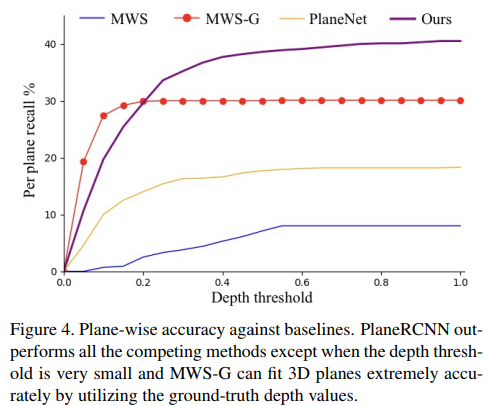
0x03 PlaneRCNN
[CVPR2019] Liu, Chen, et al. NVIDIA, Washington University in St. Louis, SenseTime, Simon Fraser University
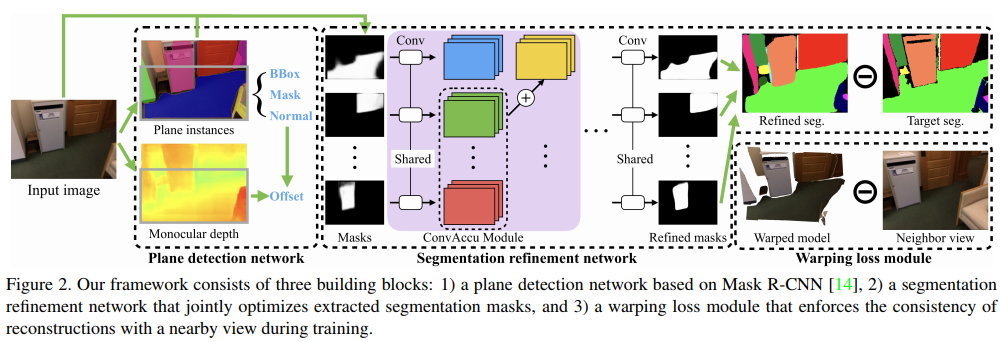
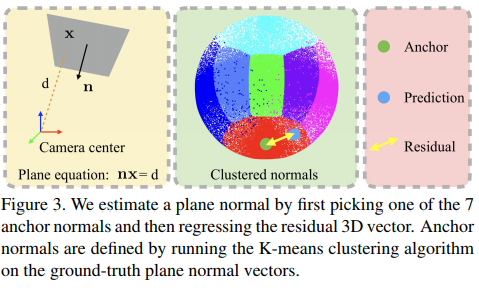
0x04 PlanarReconstruction
[CVPR 2019] Yu, Zehao, et al. ShanghaiTech University, The Pennsylvania State University
Single-Image Piece-wise Planar 3D Reconstruction via Associative Embedding
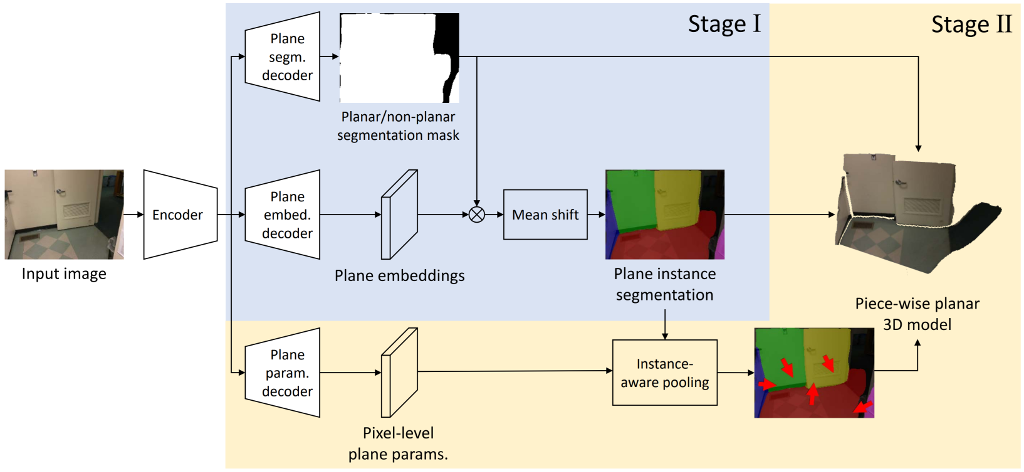
| Step | Loss |
|---|---|
| Segmentation: balanced cross entropy | |
| Embedding: discuiminative loss | |
| Per-pixel plane: L1 loss | |
| Instance Parameter: | |
| Loss |
Embedding:
associative emvedding (End-to-End Learning for Joint Detection and Grouping) ;
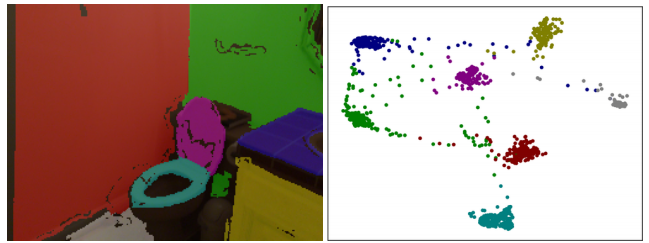
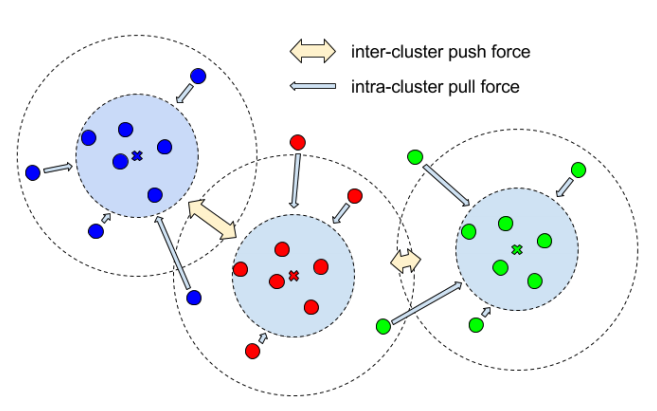
Discriminative loss function
- An image can contain an arbitrary number of instances
- The labeling is permutation-invariant: it does not matter which specific label an instance gets, as long as it is different from all otherinstance labels.
Here,
Instance Parameter Loss:
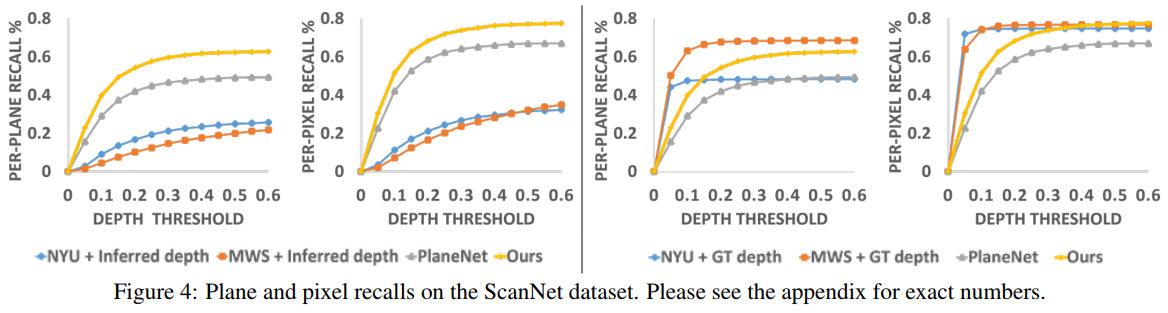
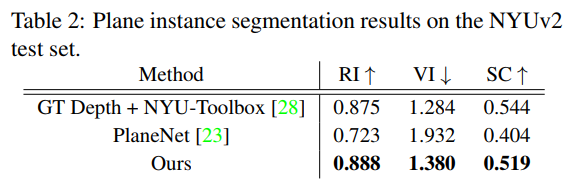
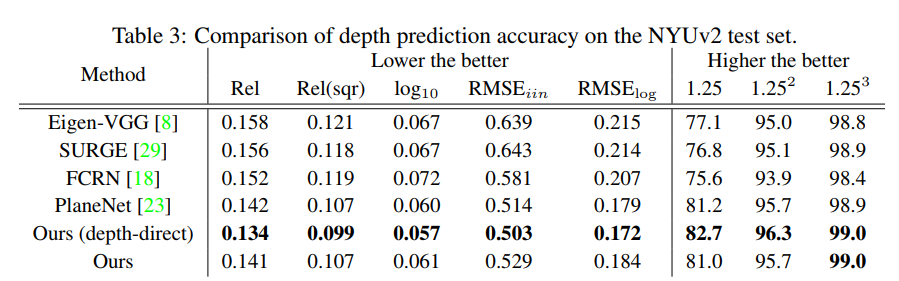
0xFF Results
PlaneNet
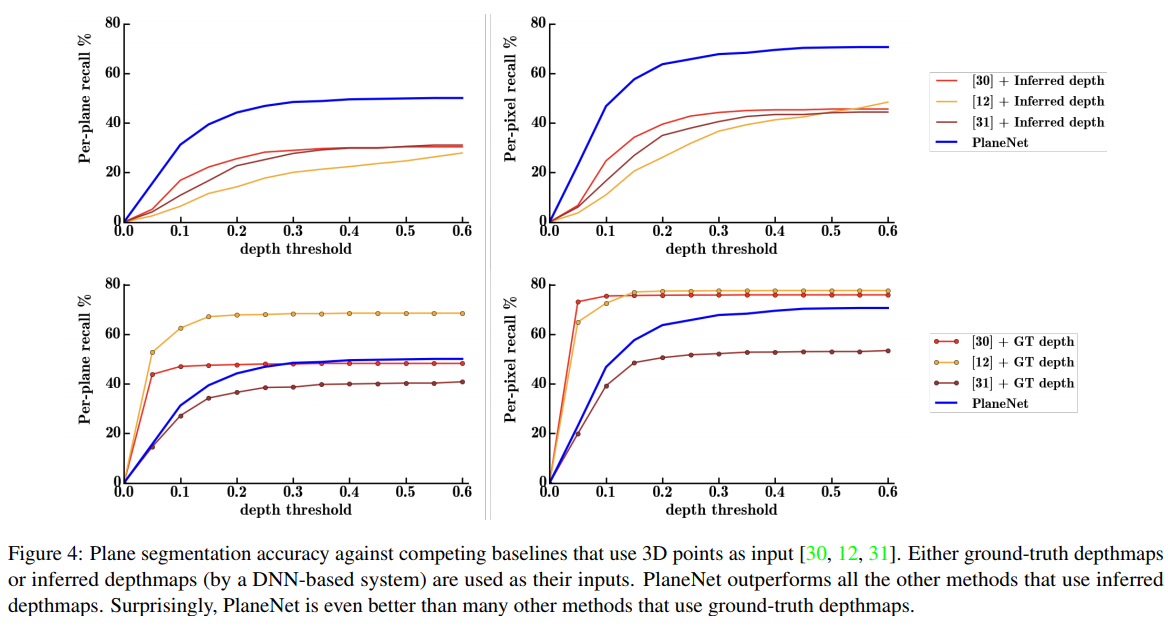
PlaneRecover
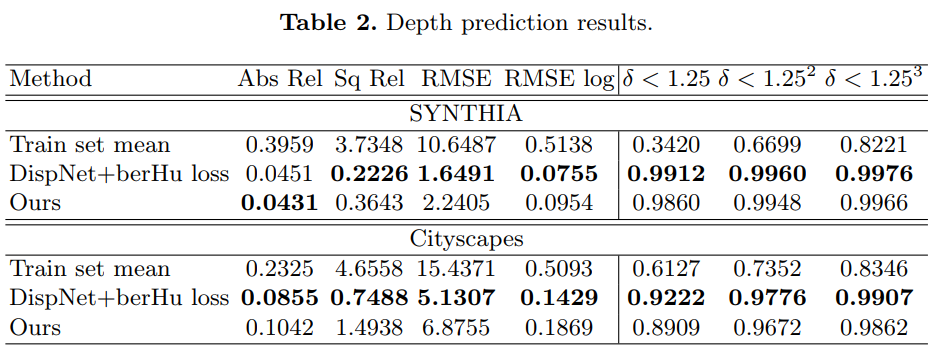
PlaneRCNN
PlanarReconstruction