有关 Chatbot 基本原理、开源框架和 Rasa
阅读了几篇关于 Chatbot 的综述、文档,Rasa 的介绍。另外,调研了一些大厂的 Chatbot 框架,包括Google 的 Dialogflow, Microsoft Bot, AWS LEX, 阿里小蜜;和开源超过 1k stars 的框架,包括 Rasa, OpenNLU, ParlAI, ChatterBot, ai-chatbot-framework。
0x01 聊天机器人
1.1 基于场景的分类
(Eleni et al., 2020) 简要的介绍了聊天机器人的基本概念,同时对两天机器人在不同场景下进行了分类:
知识领域: open domain, close domain;提供服务: interpersonal, inter-agent;目标: informative(FAQ), chat-based(conversational), Task-based;输入处理和响应生成方法: rule-based, retrieval-based, generative based;
1.2 基于计算方法的分类
(Luo Bei,2021) 对SOTA 的 chatbot 做了一个详细的综述,其中包括基于计算方法的分类 Chatbot 市面上的应用 知识库建立方法:
- a.
基于模板的聊天机器人 - b.
基于语料库的聊天机器人 - c.
基于意图的聊天机器人 - d.
基于RNN的聊天机器人 - e.
基于强化学习的聊天机器人 - f.
采用混合方法的聊天机器人
a. 基于模式匹配(模板)的聊天机器人
基于 AIML(人工智能标记语言),匹配预定义的模板。LSA(潜在语义分析)使用单词之间的相似性作为向量表示,可与作为 AIML 的兜底,当 AIML 无法匹配到问题时,使用LSA进行回复。
此方法致命的缺陷是,不会存储历史对话,可能导致循环对话。
AIML 的一个例子
1 | <aiml> |
b. 基于意图识别的 Chatbot
首先,自动语音识别模块将音频信息转换为文本,实现多媒体处理器的功能。接下来,口语理解 (SLU) 语义解析用户话语以检测用户查询的意图,从槽中提取某些信息,并形成语义框架。该模块与多模态输入分析并行。之后,DST 用于估计当前对话的状态,DPO 用于确定动作和响应;这两个组件都属于响应生成器。最后,输出适当的消息。

c. Seq2Seq 模型的原理
d. 强化学习的方法主要基于Markov决策过程,通常描述为
- 有限状态集 $S={s_i}$;
- 有限的行动集 $A={a_i}$ 描述了从一个状态到另一个状态的变换;
- 策略 $a=π(s)$ 指定在状态下执行动作的概率 $s$;
- 状态转移模型 $T(s,a,s’)=P_r(s’|s,a)$ 表示从状态 $s$ 转移到下一个状态 $s’$ 的概率;
- 奖励函数 $R(s,a,s’)$ 指定某个状态转移后的即时奖励。
通过上述定义,强化学习会找到一个最优策略,以最大化收益:
$Q_π(s,a)={max}_πE[r_t+γr_{t+1}+γ^2r_{t+2}+… \vee s_t=s, a_t=a,π]$
e. 基于各种计算方法的聊天机器人分类
| Template-based chatbot | Corpus-based chatbot | Intent-based chatbot | RNN-based chatbot | RL-based chatbot | Chatbot with hybrid approaches | |
|---|---|---|---|---|---|---|
| Techniques of knowledge management | AIML | Database and ontology | — | — | — | Depends on components |
| Techniques of response generation | Pattern matching | Text mining | SLU, DST, DPO, NLG | RNN and LSTM/GRU | RL | Ranking algorithm/embedded technology |
| Typical chatbot | ALICE (Abushawar & Atwell, 2015) | KRISTINA (Wanner et al., 2017) | Dialogflow | Shao et al. (2017) | MILABOT (Serban et al. (2018) | Song et al. (2016) |
| Characteristics | Simplicity | Well-performed knowledge management | Multi-turn responses | Wide-range communication topics; uncertain responses | Consideration of context | More complicated, but better performance |
| Suitable application | Simple and task-oriented | Applications that require large knowledge bases | Multi-turn and task-oriented | Open domain and chat-oriented | Context-oriented | Applications that require high performance with large investment |
| Development direction | Knowledge establishment and multimedia interaction | Knowledge management and response matching | User input understanding, dialogue state, and response generation | Response generation and multimedia interaction | Design for the appropriate application of RL chatbots | Ranking algorithm improvement/embedding technology |
f. 名词解释
AIML人工智能标记语言;Chatscript一个 AIML 语言的继承者,可以储存长期记忆;RiveScript一个纯文本的,用于开发聊天机器人和其他对话实体的基于行的脚本语言;ALICE人工语言互联网计算机实体;DPO对话策略优化;DST对话状态跟踪;GRU门控循环单元;LSTM长短期记忆;NLG自然语言生成;RL强化学习;RNN循环神经网络;SLU口语理解;NLP自然语言处理,是人工智能的一个领域,探索计算机对自然语言文本或语音的处理;NLU自然语言理解,NLP 任务的核心。它是一种实现自然用户界面(例如聊天机器人)的技术。 NLU 旨在从自然语言用户输入中提取上下文和含义,这些输入可能是非结构化的,并根据用户意图做出适当的响应。它识别用户意图并提取特定的实体;intent意图,表示用户所说的内容与聊天机器人应采取的操作之间的映射;actions操作,对应于聊天机器人在用户输入触发特定意图时将采取的步骤,并且可能具有用于指定有关它的详细信息的参数。意图检测通常被表述为句子分类,其中为每个句子预测单个或多个意图标签;entity实体,是一种从自然语言输入中提取参数值的工具。例如,考虑句子“希腊的天气如何?”。用户意图是学习天气预报。实体值为希腊。因此,用户要求希腊的天气预报。实体可以是系统定义的或开发者定义的。例如,系统实体 @sys.date 对应于标准日期引用,如 2019 年 8 月 10 日或 8 月 10 日。域实体提取通常被称为槽填充问题,被表述为一个顺序标记问题,其中提取句子的各个部分并用域实体标记;contexts上下文,是存储用户所指或谈论的对象的上下文的字符串。例如,用户可能会在他的以下句子中引用先前定义的对象。用户可以输入“打开风扇”。这里要保存的上下文是风扇,这样当用户说“关闭它”作为下一个输入时,可以在上下文“风扇”上调用意图“关闭”。
0x02 Rasa
区别与算法研究,搭建一个 Chatbot 更多的工作是构建知识库、意图、接口,搭建回归测试保证算法的鲁棒性等,选择一个流行的对话框架可以减少研究人员对工程代码的编写。
其中,谷歌、微软、亚马逊、阿里这几个大厂的 Chatbot 服务均需要收费。
- Bocklisch et al. 2017, Rasa: Open Source Language Understanding and Dialogue Management 介绍了 rasa 的功能和先进性;
- Hu Xiaoquan et al. 2021, Conversational AI with Rasa[M]详细的介绍了 rasa 的使用方法。
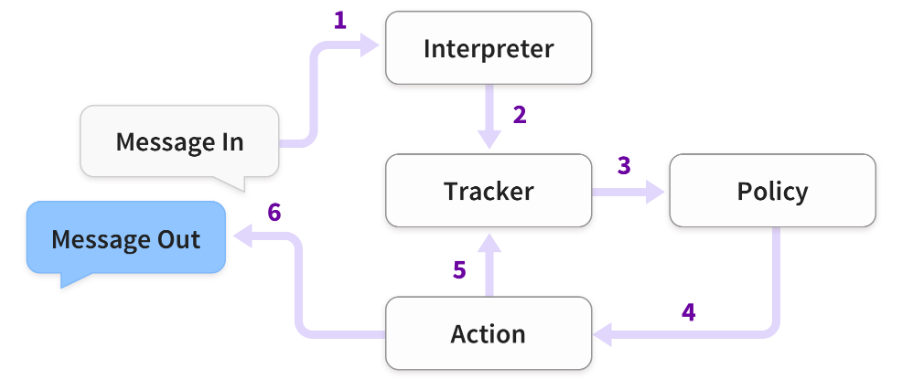
2.1 架构
- 收到消息并传递给解释器(例如RASA NLU)以提取意图,实体和任何其他结构化信息。
- 跟踪器维护会话状态。它收到已收到新消息的通知。
- 策略接收跟踪器的当前状态。
- 策略选择接下来的行动。
- 所选操作由跟踪器记录。
- 执行该操作(这可以包括向用户发送消息)。
- 如果预测的行动不是’听’,请返回步骤3
2.2 动作(Actions)
简单的对话, 或任意函数,包含对话中的历史信息。
2.3 松耦合的 NLU 模块
比如 spacy_sklearn, spaCy, GloVe, ner_crf.
2.4 策略
通过以下特征定义下一步action:
- 最后一个动作是什么
- 最近用户消息中的意图和实体
- 当前定义了哪些槽
2.5 方便阅读的训练数据格式, json
1 | { |
2.6 machine teaching for supervised learning
提供可能的动作和概率,生成新的训练数据
1 | what is the next action for the bot? |
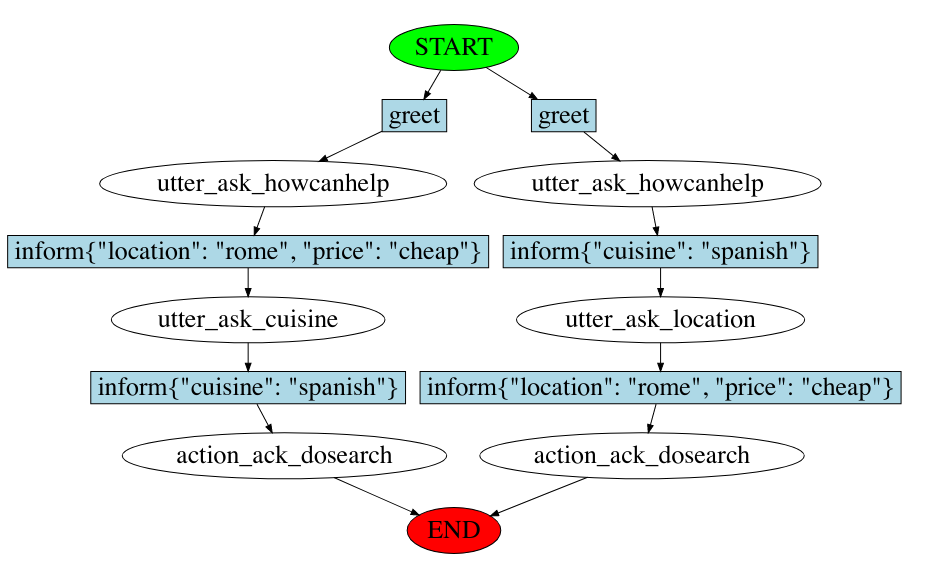
2.7 对话图的可视化
2.8 在生产环境中部署
支持 docker,线程/进程并行的 HTTP API.
2.9 支持的数据
支持的数据包括由按意图分类的用户话语组成的 NLU 数据,其中还可以包括实体、正则表达式和查找表等额外信息;此外还可以包含 story base 和 rule base 的对话数据,如下。其它的例子参见 RASA: Training Data Format:
a. Entities
1 | nlu: |
b. Synonyms
1 | nlu: |
c. Rules
1 | rules: |
(To be continued…)
0xFF 其它有用的资料:
- Conversational AI with Rasa.pdf
- NLP民工的乐园: 几乎最全的中文NLP资源库
- Awesome-Chatbot
- 中文公开聊天语料库
- zhaoyingjun/chatbot
- 开闲聊常用语料和短信
- 如何打造你自己的聊天机器人
wechaty: 一个可以把微信/京东客服等变成聊天机器人的工具,让运营人员更多的时间思考如何进行活动策划、留存用户,商业变现